Warum wir diesen Artikel geschrieben haben
Wer Software baut, die länger als zwei Jahre im Einsatz bleibt, kennt das Muster: Anfangs geht alles schnell, dann wird jede Änderung zäh. Irgendwann traut sich niemand mehr, eine Bibliothek zu aktualisieren, weil unklar ist, was dabei zerbricht. Clean Architecture (Robert C. Martin, Originalpost 2012, Buch 2017) ist ein Werkzeug gegen genau dieses Problem, allerdings nur, wenn man sie pragmatisch einsetzt und nicht als Selbstzweck. Dieser Artikel fasst zusammen, was wir in unseren Projekten gelernt haben.
Grundprinzipien
Clean Architecture, geprägt von Robert C. Martin, beschreibt keine neue Idee, sondern bündelt mehrere ältere Ansätze (Hexagonal Architecture / Ports & Adapters von Alistair Cockburn 2005, Onion Architecture, DCI (Data, Context, Interaction)) zu einer konsistenten Form. Das Ziel ist, fachliche Regeln von technischen Details zu entkoppeln, so dass Frameworks, Datenbanken und UI-Technologien austauschbar bleiben, während der Kern der Anwendung stabil weiterläuft.
Die Dependency Rule
Das zentrale Prinzip heißt Dependency Rule: Abhängigkeiten zeigen ausschließlich von außen nach innen. Die Domäne kennt weder die Datenbank noch das HTTP-Framework. Umgekehrt dürfen äußere Schichten die Domäne kennen, aber niemals umgekehrt. Dieses einfache Prinzip hat massive Auswirkungen, weil es bestimmt, wie Interfaces definiert und wo Abstraktionen platziert werden.
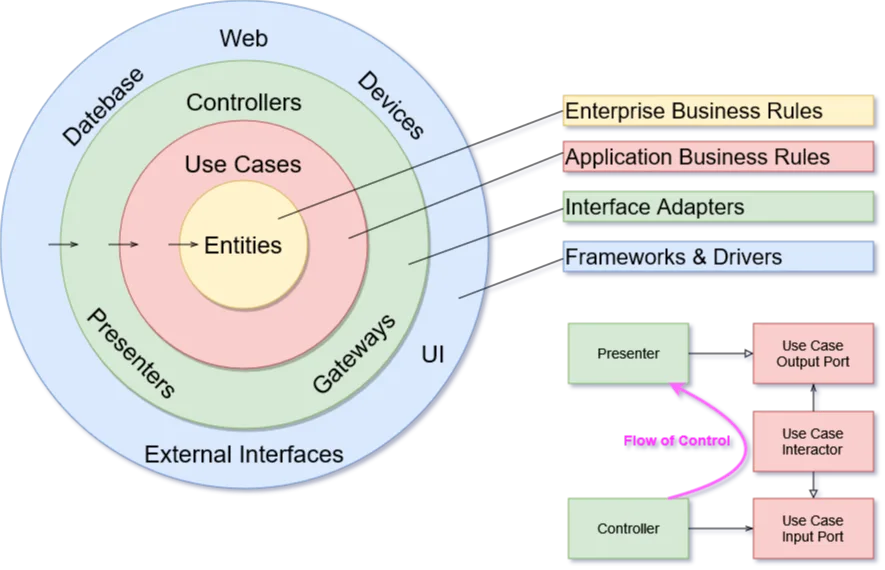 Die konzentrischen Schichten der Clean Architecture
Die konzentrischen Schichten der Clean Architecture
Die Schichten
In der klassischen Darstellung gibt es vier konzentrische Schichten, in der Praxis arbeiten wir oft mit drei bis fünf, je nach Umfang des Projekts:
- Entities bilden die unternehmensweiten Geschäftsregeln ab. Sie sind unabhängig von einer konkreten Anwendung und könnten theoretisch in mehreren Systemen wiederverwendet werden.
- Use Cases enthalten anwendungsspezifische Logik. Ein Use Case beschreibt was die Software leisten soll, nicht wie sie es technisch umsetzt.
- Interface Adapters übersetzen zwischen Use Cases und der Außenwelt: Controller, Presenter, Repository-Implementierungen, Mapper.
- Frameworks & Drivers sind die austauschbaren Teile: Spring Boot, die konkrete Datenbank, ein Message Broker, das Frontend-Framework.
In kleineren Projekten ziehen wir die Entities- und Use-Case-Schicht manchmal zu einer Domain-Schicht zusammen. In großen Domänen mit komplexen Regeln trennen wir umgekehrt Domain Services und Application Services zusätzlich. Die Anzahl der Schichten ist weniger wichtig als die konsequente Einhaltung der Dependency Rule.
SOLID als Fundament
Clean Architecture baut auf den SOLID-Prinzipien auf. Besonders prägend sind zwei davon: Single Responsibility sorgt dafür, dass jede Komponente einen klaren Grund für Änderungen hat; Dependency Inversion ermöglicht überhaupt erst, dass innere Schichten nichts über äußere wissen müssen. Die übrigen drei, Open-Closed, Liskov Substitution und Interface Segregation, sind Folgerungen daraus. Wer SOLID ernst nimmt, kommt fast automatisch bei Clean Architecture an.
Was die Trennung bringt
Die Schichtung hat ganz praktische Konsequenzen für den Alltag: Tests werden schnell, weil die Domäne ohne Datenbank und ohne HTTP-Stack läuft. Frameworks werden austauschbar. In mehreren Projekten haben wir Persistenzschichten oder Web-Frameworks gewechselt, ohne die Geschäftslogik anzufassen. Neue Entwickler finden sich schneller zurecht, weil die Grenzen der Verantwortlichkeiten sichtbar sind. Und die Domänenlogik bleibt lesbar, weil sie nicht von technischem Rauschen überlagert wird.
 Vorteile der Clean Architecture im Überblick
Vorteile der Clean Architecture im Überblick
Praktische Implementierung
Die Theorie ist elegant, die Umsetzung erfordert Disziplin. Ein paar Dinge, die sich in unseren Projekten bewährt haben.
Projektstruktur
Wir starten meistens mit einer Struktur, die die Schichten auch physisch trennt, entweder über Modulgrenzen oder zumindest über klar separierte Package-Hierarchien:
project/
├── domain/ # Entities und Business Rules
├── application/ # Use Cases und Application Services
├── interfaces/ # Controller, Presenter, Mapper
└── infrastructure/ # Persistenz, externe Services, FrameworksBei Maven- oder Gradle-Projekten trennen wir diese Schichten gerne in eigene Module. Der große Vorteil: Der Build-Werkzeugkette fällt es sofort auf, wenn jemand eine verbotene Abhängigkeit einführt. Die Domain darf schlicht nicht auf die Infrastruktur zugreifen. Kompilierfehler statt Code Review.
Domain Layer
Die Domain-Schicht ist das Herzstück. Hier leben die Regeln, die fachlich relevant sind und nicht an Technologie hängen. Ein Beispiel aus einem unserer Projekte im Zahlungsverkehr: Die Regel „eine SEPA-Überweisung über 100.000 EUR erfordert eine zweite Freigabe” steht direkt als Invariante in der Entity, nicht verteilt in Service-Klassen oder Datenbank-Triggern. Das macht sie sicht- und testbar.
Wichtig ist uns dabei die Ubiquitous Language aus dem Domain-Driven Design: Die Begriffe der Fachabteilung landen unverändert im Code. Wenn der Fachbereich von einem „Gegenkonto” spricht, heißt die Klasse auch so. Das klingt trivial, spart aber später viele Missverständnisse zwischen Fachseite und Entwicklung.
 Typischer Datenfluss in einem Use Case
Typischer Datenfluss in einem Use Case
Use Cases und Application Services
Use Cases orchestrieren die Domain-Objekte. Sie beschreiben einen fachlichen Ablauf (etwa „Überweisung einreichen”, „Kunde anlegen”, „Rechnung stornieren”) und delegieren die eigentliche Logik an die Entities. Ein Use Case ist typischerweise eine kurze Methode, die Eingabe entgegennimmt, Entities lädt, eine Operation ausführt und das Ergebnis zurückgibt.
Eine Sache, die wir erst lernen mussten: Use Cases sollten keine Geschäftsregeln enthalten. Wenn im Use Case steht „wenn der Betrag größer als X, dann …”, ist das ein Indiz, dass die Regel in die Entity gehört. Der Use Case koordiniert, er entscheidet nicht.
Interface Adapters
Die Adapter-Schicht ist die Übersetzungsebene zwischen Use Cases und der Außenwelt. Controller nehmen HTTP-Requests entgegen, mappen sie auf Use-Case-Eingaben und geben die Antwort zurück. Repository-Implementierungen sprechen mit der Datenbank und liefern Entities zurück. Gateways kapseln Aufrufe an externe Services.
Was oft unterschätzt wird: Die Mapping-Arbeit in dieser Schicht ist echter Code und verdient echte Tests. Wir haben schon erlebt, dass ein falsches Datumsformat im Presenter mehr Produktionsprobleme verursacht hat als jede Domain-Regel.
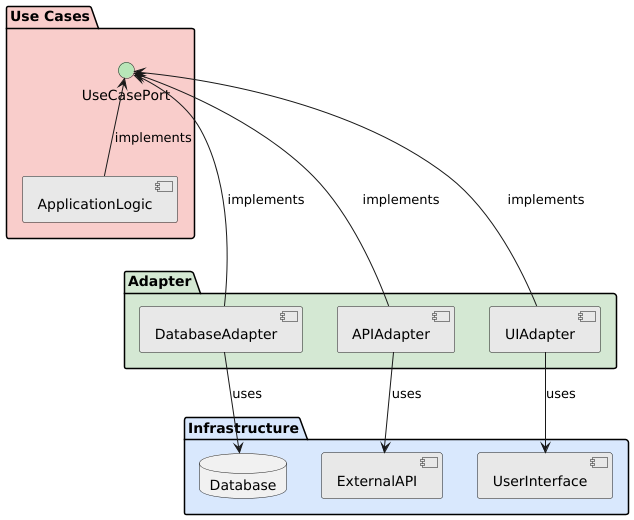 Implementierung des Adapter Patterns
Implementierung des Adapter Patterns
Wer tiefer einsteigen will, findet unter Das Adapter Pattern in Clean Architecture weiterführende Erklärungen.
Testing-Strategien
Gute Testbarkeit ist einer der Hauptgründe, überhaupt Clean Architecture einzuführen. In der Praxis ergibt sich daraus eine natürliche Testpyramide: Viele schnelle Unit Tests für Entities und Use Cases, die weder Datenbank noch Framework brauchen. Weniger Integrationstests, die Adapter und Infrastruktur prüfen. Und einige wenige End-to-End-Tests, die das Zusammenspiel aller Komponenten verifizieren.
Für externe Abhängigkeiten verwenden wir Mocks oder Test Doubles, aber nur an den Grenzen der Domäne, nie innerhalb. Und wir schreiben Architekturtests (mit Tools wie ArchUnit), die automatisiert prüfen, ob die Dependency Rule eingehalten wird. Ein grüner Compiler ist noch keine Garantie für saubere Abhängigkeiten.
 Korrekte Implementierung von Boundary Crossings
Korrekte Implementierung von Boundary Crossings
Wirtschaftlicher Nutzen
Clean Architecture verursacht initial Mehraufwand: zusätzliche Interfaces, mehr Mapping, eine Lernkurve im Team. Der Nutzen zeigt sich erst nach einigen Monaten, dann aber deutlich.
Wartbarkeit
Fehler lassen sich schneller isolieren, weil die Schichten klar getrennt sind. Ein Bug in der Repräsentation lässt die Domänenlogik unberührt, ein Datenbankproblem verlangt keinen Blick auf den Use Case. Neue Entwickler brauchen weniger Einarbeitungszeit, weil die Struktur selbstbeschreibend ist. Und technische Schuld akkumuliert langsamer, weil Änderungen lokal bleiben.
 Wartungskosten: Traditionelle vs. Clean Architecture
Wartungskosten: Traditionelle vs. Clean Architecture
Time-to-Market
Auf die Dauer wird die Entwicklung schneller, nicht langsamer. Module können parallel entwickelt werden, weil Schnittstellen früh stabil sind. Komponenten lassen sich wiederverwenden. Und Features lassen sich inkrementell ausliefern, weil die Domäne nicht in jedem Schritt komplett durchgereicht werden muss.
Risikominimierung
Die wichtigste Risikominderung ist Technologieflexibilität. Wir haben in mehreren Projekten größere Refactorings durchgeführt (Migration von Oracle zu PostgreSQL, Wechsel von JSF zu React, Umstellung von monolithischer Deployment-Form zu Services), ohne dass die Geschäftslogik angefasst werden musste. Das ist der eigentliche ROI: nicht Einsparung pro Stunde, sondern die Fähigkeit, das System über Jahre weiterzuentwickeln, ohne es neu schreiben zu müssen.
Wann sich der Aufwand lohnt
Ehrlich gesagt: nicht immer. Für ein einmaliges Skript, einen Prototyp oder eine kurzlebige Marketing-Aktion ist Clean Architecture Overkill. Wir setzen sie dort ein, wo Software absehbar über Jahre läuft, wo sich Anforderungen ändern werden, wo Compliance und Prüfbarkeit eine Rolle spielen, oder wo das Team im Laufe der Zeit wechselt. In diesen Fällen zahlt sich die Investition regelmäßig aus.
Erfahrungen aus realen Projekten
Schrittweise einführen statt Big Bang
Bestandssysteme lassen sich selten in einem Schritt umstellen. Wir gehen meistens iterativ vor: Wir identifizieren einen fachlichen Bereich mit hohem Änderungsdruck, bauen ihn nach Clean-Architecture-Prinzipien neu und lassen das alte System drumherum stehen, bis der nächste Bereich dran ist. Das Strangler Fig Pattern ist dafür ideal.
Architekturregeln automatisieren
Guidelines im Wiki sind schön, halten aber keinen Hackathon über. Was wirklich hilft: Architekturtests, Module mit harten Grenzen, Linter-Regeln und Code-Owner-Einstellungen, die ungeplante Abhängigkeiten verhindern. Wir prüfen in jedem CI-Build, ob Packages die erlaubten Grenzen respektieren.
Häufige Fallstricke
Die meisten Probleme entstehen nicht durch die Architektur selbst, sondern durch ihre übereifrige Anwendung. Ein paar wiederkehrende Muster:
- Überabstraktion: Für jede Klasse ein Interface, auch wenn es nur eine Implementierung gibt. YAGNI ignorieren macht Code nicht flexibler, nur schwerer lesbar.
- Schichtenvermischung: JPA-Annotationen in Domain-Entities, weil es schneller geht. Später lässt sich die Persistenz dann doch nicht austauschen.
- Anämische Domain: Entities werden zu reinen Datenklassen, alle Logik landet in Services. Das Ergebnis ist prozedurale Programmierung mit objektorientierter Syntax.
- Mapping-Müdigkeit: Wenn es zwischen drei Schichten jeweils eigene DTOs gibt, verbringt man mehr Zeit mit Mappern als mit Logik. Manchmal ist ein pragmatisch gemeinsam genutztes Objekt die bessere Wahl.
- Performance-Paranoia vor Messung: Bevor man Clean Architecture wegen angeblicher Performance-Nachteile verwirft, sollte man messen. Die Engpässe liegen fast nie in der Schichtung.
Herausforderungen und Lösungen
Performance
Zusätzliche Schichten bedeuten zusätzliche Objekterzeugung und Mapping. Das ist in den meisten Anwendungen irrelevant, der Unterschied wird von einem einzigen Datenbankzugriff mehrfach überdeckt. Wo wir genauer hinschauen: bei Batch-Verarbeitung großer Datenmengen, bei Streaming-Anwendungen und bei Low-Latency-Komponenten. Dort setzen wir punktuell auf Lazy Loading, Object Pooling oder direktes Streaming, ohne die Gesamtarchitektur zu kompromittieren.
Legacy-Integration
Wenn ein bestehendes System weiterlaufen muss, schützen wir die neue Architektur mit einem Anti-Corruption Layer. Das ist eine Übersetzungsschicht, die Altdaten in die Sprache der neuen Domäne überführt und umgekehrt. So bleibt die neue Domäne sauber, und der Altbestand kann abgelöst werden, wenn es soweit ist, nicht weil das Dogma es verlangt.
 Strategien zur Legacy-Integration
Strategien zur Legacy-Integration
Verteilte Systeme
In Microservices-Umgebungen wird die Dependency Rule nicht überflüssig, sie wirkt nur auf einer anderen Ebene. Jeder Service bekommt seine eigene interne Schichtung. Zwischen Services laufen definierte Kontrakte mit Versionierung. Für verteilte Transaktionen setzen wir CQRS, Event Sourcing und das Saga-Pattern (Garcia-Molina/Salem 1987, in Microservices popularisiert durch Chris Richardson) ein, je nachdem, welche Konsistenzgarantien die Fachseite braucht. Zwei-Phasen-Commit über Servicegrenzen hinweg vermeiden wir konsequent.
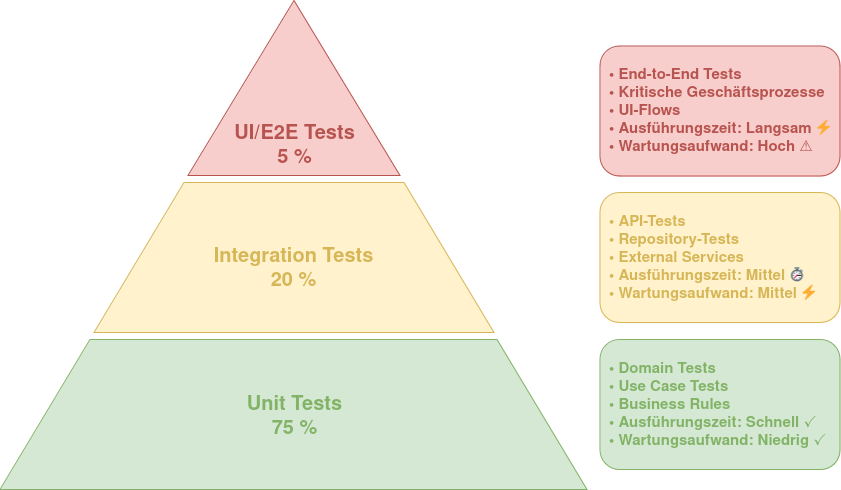 Test-Pyramide in Clean Architecture
Test-Pyramide in Clean Architecture
Häufig gestellte Fragen
Ist Clean Architecture das gleiche wie Hexagonal Architecture?
Nein, aber die Ideen überschneiden sich stark. Hexagonal Architecture (von Alistair Cockburn) fokussiert auf die Ports-and-Adapters-Metapher und unterscheidet primäre und sekundäre Adapter. Clean Architecture erweitert dieses Bild um die explizite Trennung von Entities und Use Cases und die konzentrische Darstellung. In der Praxis führen beide Ansätze zu sehr ähnlichen Strukturen.
Brauche ich für jede Klasse ein Interface?
Nein. Interfaces sind sinnvoll, wo eine Grenze überwunden wird, typischerweise an den Schichten-Übergängen, an denen die Dependency Rule greift. Innerhalb einer Schicht reicht meistens die konkrete Klasse. Ein Interface ohne wechselnde Implementierung ist meistens Ballast.
Ist Clean Architecture für kleine Projekte übertrieben?
Oft ja. Für ein kurzlebiges Projekt mit klarem Umfang reicht eine einfachere Struktur. Die Frage ist weniger die Größe als die erwartete Lebensdauer: Ein kleines, aber langlebiges System profitiert; ein großer Einmal-Import-Job profitiert kaum.
Wie verhält sich Clean Architecture zu Microservices?
Die beiden Konzepte arbeiten auf unterschiedlichen Ebenen. Microservices sind ein Deployment-Muster, Clean Architecture ein Code-Muster innerhalb eines Dienstes. Beide lassen sich kombinieren: Ein Microservice kann intern sehr wohl nach Clean Architecture aufgebaut sein. Ohne interne Struktur wird ein Microservice schnell zum Distributed Monolith.
Wie viel Mehraufwand bedeutet Clean Architecture?
In der Einführungsphase rechnen wir mit 10 bis 20 Prozent zusätzlicher Zeit, vor allem für Mapping, Interface-Definitionen und Schulungen im Team. Nach drei bis sechs Monaten ist die Struktur eingespielt und zahlt sich durch höhere Änderungsgeschwindigkeit aus. Die konkrete Zahl hängt stark vom Vorwissen des Teams und der Projektart ab.
Funktioniert Clean Architecture auch mit funktionalen Sprachen?
Ja, und oft sogar leichter. Funktionale Sprachen erzwingen durch Immutability und reine Funktionen viele Eigenschaften, die in OO-Sprachen mühsam hergestellt werden müssen. Die Dependency Rule bleibt gleich, nur die Ausdrucksmittel ändern sich. Higher-Order Functions ersetzen oft das, wofür man sonst Interfaces bräuchte.
Wo fängt man an, wenn man Clean Architecture lernen will?
Das Originalbuch von Robert C. Martin ist ein guter Startpunkt, aber abstrakt. Wir empfehlen, ein kleines Projekt nach den Prinzipien umzusetzen, idealerweise einen fachlich überschaubaren Use Case mit klarer Domäne. Die Eigenheiten versteht man am besten, wenn man einmal mit dem eigenen Code gegen die Dependency Rule gestoßen ist.
Zusammenfassung
Clean Architecture ist kein Allheilmittel und auch keine exotische Methode, sondern eine pragmatische Sammlung von Regeln, die Software über Jahre wartbar halten. Der Schlüssel liegt in der Konsequenz bei den Abhängigkeiten und in der Bereitschaft, technische Details konsequent nach außen zu verlagern. Wer das erst gewohnt ist, mag die initiale Disziplin nicht missen. In unseren Projekten, insbesondere dort, wo Compliance, lange Lebensdauer und wechselnde Teams aufeinandertreffen, ist sie zum Standard geworden.